-
Why you (probably) don't wanna use SSL client certificates
This is a bit of a fringe issue (outside online banking at least), but in this blog post I’ll try to list a few of my issues with running an API service that uses SSL client certificates to authenticate its users (‘client applications’ to be more specific).
In my case the client certificates were already in place, so using them kinda made sense (but looking back, using API keys instead of client certificates would’ve saved me a bit of headache).
If you’re thinking about using client certificate based authentication for one of your projects, maybe I’ll be able to convince you otherwise.But let’s start:
Finding help
You’re gonna feel pretty much alone with your problems. Most tools and frameworks (read: at least the ones I’ve used) seem to support client certs, but I’ve found it hard to find much help on internet forums or stackoverflow.
Bug hunting
It is quite hard to pin down and fix certificate issues. You’ve basically doubled the problem surface of just using server-side certificates (Missing root certificates, incomplete certificate chain, clients set to the wrong system date, …).
Client certificate validation errors are often cryptic (no pun intended). Tell me, what’s wrong here for example:
curl: (35) error:14094410:SSL routines:SSL3_READ_BYTES:sslv3 alert handshake failureOk great, the handshake failed. But why did it fail, I ask?
And your server probably doesn’t even see the failed request(s) (and is therefore unable to handle them with nice and clean error messages) (unless you configured client certificates to be optional and handle things in your application).
-
Is it (pseudo)random? (part 1)
Nearly every software project needs random number generators in one way or another. Sometimes all you want to do is roll a dice or shuffle a list (like a deck of cards or the songs in a playlist).
Or you use random string identifiers for your web applications (like the video URLs on youtube or the document IDs in pretty much any NoSQL database). And there are good reasons to use random instead of sequential IDs, but that’s another topic.The extreme end of dealing with randomness is obviously cryptography. But the details on that blow way past the scope of this series of blog posts.
So if you’re looking for advice on that: do plenty of research (and: NEVER do your own crypto!)Whatever your use case, I’d argue that you should take one thing into consideration: predictability.
If you write a simple dice or card game (or pretty much all client software - again: other than crypto), you probably won’t (and shouldn’t have to) care much about the quality of your random data.But as soon as we’re talking about web services predictability becomes an issue. You wouldn’t want people to guess your ‘secret’ IDs - or the random numbers your online game servers generate.
Sometimes on the other hand you even want that predictability: Let’s look at Microsoft’s FreeCell game. It allows you to see (and select) the individual game’s ID so you can replay specific games or challenge others. Internally, the game uses that ID as seed (initial value) for its PRNG (PseudoRandom Number Generator).
And whenever you seed a PRNG with the same value, you’ll get the same sequence of random-looking numbers (hence the prefix ‘pseudo’).
For a card game that’s perfect (since you’re gonna use a RNG to shuffle the deck anyway).it’s probably worth mentioning that FreeCell is a so called perfect information game - you can see all the cards from the very beginning, so ‘cheating the RNG’ doesn’t really make sense there anyway
When you generate hard-to-guess IDs or crypto keys though, that kind of predictability is an absolute no-go.
But we’re getting ahead of ourselves. This part of the (three part) series will cover the basics of generating non-sensitive random numbers.
-
Migrating from WordPress to Jekyll
I’ve never considered myself much of a writer (which should be evident when you look at the dates of my previous posts :) ). But every now and then there’s some online research (for work or other reasons) that merits a blog post.
I’ve set up my blog in 2009 on my private server using WordPress. And because I wanted to prevent malicious code from taking down the whole server, I configured each site to run on separate linux user accounts.
Over the years there’ve been several reasons why I’ve been kinda unhappy with that setup. I’ll try to remember (and maybe will even look up) some of the details, but I can’t guarantee their accuracy.
For one, I never wanted to limit myself to either English or German content. After browsing WordPress’ plugin directory for a bit, I’ve found a mulilanguage plugin. That worked mostly well but pretty much meant that from that point on I had to write each blog post twice (and raising that barrier meant fewer posts in the end).
Because I’ve basically used PHP in CGI mode (for the setuid stuff, remember?), a new interpreter instance had to be started for each request (at least at some point - I think I moved to a slightly different approach at some point when upgrading the server). That caused some quite terrible response times (at least that’s what the perfectionist inside me thought).
I ended up installing a plugin that prerendered most pages and spews out static files. A littlemod_rewritemagic and all pages were served statically (and apparently a lot of non-essential links broke, but I never seemed to notice until now).The third issue that kept bugging some part of me was the WYSIWYG editor (that kept producing - at least to the eyes of someone who writes HTML by hand from time to time - sub-par output).
At one point I had the idea of looking for a way to write blog posts in MarkDown. And guess what, there’s a plugin for that.I’d argue that every single one of these plugins kinda stretches the limits of WordPress in another direction. And looking back I’m really surprised it actually worked as well as it did.
-
My routine for setting up debian hosts
In this post I’ll try to sum up the steps I take right after I get my hands on a vanilla debian installation (the same applies to Ubuntu or other debian derivatives).
Some of these commands are interactive (they can be automated though). I’m not doing this often enough to justify an automation.
First I install a few convenience packages (depending on the installation, some of them may already be present)
apt-get update && apt-get upgrade apt-get install locales openssh-server sudo ntp wget curl mosh less most vim bash-completion htop iftop iotop python3-pip smartmontools rsync gitAfter that, I’ll set up locales and the system’s timezone
dpkg-reconfigure locales tzdata -
Stress-Test für HTTP-Seiten
Kürzlich war ich auf der Suche nach einem Tool, mit dem ich diesen Blog Stress-Testen konnte. Ich wollte sehen, was passiert, wenn (falls…) einmal unter Last kommt.
Es gibt verschiedene Dienste, die genau das im Internet anbieten, aber eine schnelle Suche hat nur solche zu Tage gebracht, die entweder Geld für die Tests verlangen (was ich bei der Menge des anfallenden Traffics auch verstehe) oder einen Gratis-Test nur gegen Veröffentlichung der Ergebnisse anbieten (z.B. loadimpact.com).
Also war ich auf der Suche nach einer leicht zu verwendenden Client-Lösung. Wiederum nach kurzer Web-Recherche stieß ich auf
ab, was für Apache Benchmark steht und angenehmerweise schon mit Apache ausgeliefert wird (z.B. im Paket apache-utils unter Debian/Ubuntu). Es ist ziemlich einfach zu verwenden (Details in der manpage), hält sich jedoch auch schlicht, d.h. es wird nur die angegebene URL abgefragt, keine Bilder, JavaScript, CSS oder was auch immer noch mit ausgeliefert werden würde. Aber in Verbindung mit der Netzwerk-Requestansicht der Developer-Tools des Browsers (in meinem Fall Chrome) lassen sich die langsameren Requests relativ leicht erkennen: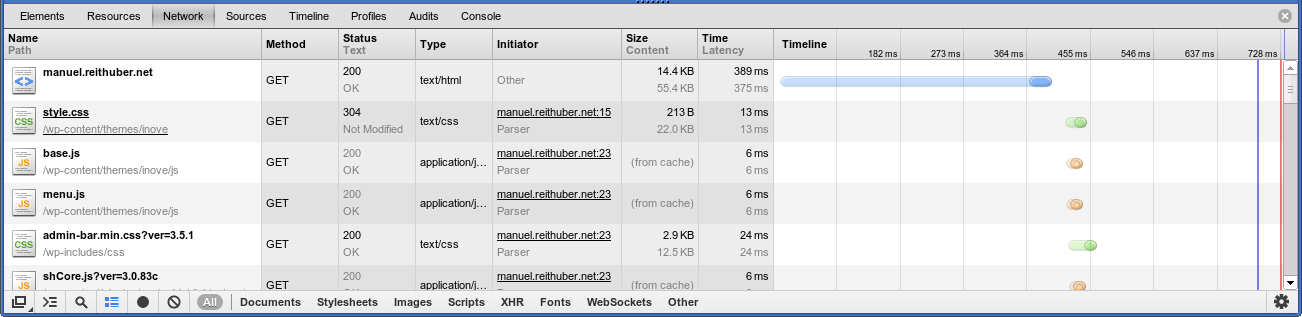
Chrome's Request timing zeigt, dass es Verbesserungsbedarf gibt (bzw. gab)
-
Interface for default route in Qt (on Linux)
Sometimes one needs to find out programmatically on which interface the default route is on. To do this in Qt, the following snippet can be used on Linux and probably other Unices (where everything’s a file ;)).
I used this snippet to prevent MediaTomb from listening on the wrong interface, but there are definitely other use cases as well:
QFile routeFile("/proc/net/route"); QString rc; if (!routeFile.open(QFile::ReadOnly)) qWarn("Couldn't read routing information: %s", qPrintable(routeFile.errorString())); QByteArray line; while (!(line = routeFile.readLine()).isNull()) { QList<QByteArray> parts = line.split('\t'); QByteArray intf = parts[0]; QByteArray route = parts[1]; QByteArray mask = parts[7]; // Find make sure the destination address is 0.0.0.0 and the netmask empty if (route == "00000000" && mask == "00000000") { rc = intf; break; } } return rc;In the shell, you’d do something like this:
cut -f1,2,8 /proc/net/route --output-delimiter=:|grep 00000000:00000000$|cut -d: -f1 -
MP3-Support for Chromium
I’ve been playing around with the HTML5
<audio>tag for some time now, always having trouble to play back Icecast Streams in Chrome (while they were working in Firefox; both apt-getted from the Ubuntu repos). Chrome was requesting the Stream and actively downloading it (which I observed using Chrome’s webdev-tools).First I thought that Chrome (or to be more specific: Chromium) attempts to cache the whole file (probably due to a missing Content-length header) before starting to play.
But when I had the same issue again today I thought that it might be a licensing issue in the open source version of Google’s browser. A quick web research confirmed that guess.
To solve that problem it’s sufficient to simply install the ffmpeg-extra codec package for chromium:
sudo apt-get install chromium-codecs-ffmpeg-extraAfter restarting the browser everything works as expected and the only thing I’ll have to worry about is which javascript plugin to use to properly handle browsers not supporting HTML5 audio (audio.js looks promising btw.)
-
Remoteregistry aus der Ferne aktivieren
Falls der Versuch, sich mit einer Netzwerkregistrierung zu verbinden (wie im vorigen Post Remotedesktopverbindung aus der Ferne aktivieren), fehlschlägt, kann diese relativ einfach (ebenfalls übers Netzwerk) aktiviert werden.
Benötigt wird dazu nur ein erreichbarer Windows-PC mit Computerverwaltung.
Zuerst muss die Computerverwaltung lokal geöffnet werden (am einfachsten geht das mMn mit einem Rechtsklick auf den Arbeitsplatz (z.b. im Startmenü, am Desktop oder im Explorer) und anschließendem Klick auf Verwalten):

Dann im Menü Aktion auf Verbindung mit einem anderen Computer herstellen:

-
Remotedesktopverbindung aus der Ferne aktivieren
Gerade erst gestern hatte ich das Problem, mich bei einem Kunden-PC entfernt anmelden zu müssen, bei dem die Remotedesktopverbindung deaktiviert war.
Glücklicherweise lässt sich diese aber per Registry aktivieren (welche wiederum Netzwerktauglich ist).
Dazu öffnet man einfach lokal den Registry-Editor (win+r, regedit):

klickt im Menü Datei auf Mit Netzwerkregistrierung verbinden

-
DNS Dos and Don'ts
Hier mal ein paar Dinge, die man beim Domain-Verwalten beachten sollte und meist selbst “schmerzvoll” erfahren musste…
(Alle Domainnamen sind durch example-Domains ersetzt)
MX-Record als IP
Heute habe ich auf einer meiner Domains beim Senden einer Nachricht folgenden Bounce bekommen:
550-It appears that the DNS operator for example.org 550-has installed an invalid MX record with an IP address 550-instead of a domain name on the right hand side. 550 Sender verify failedSchnell eine mail.example.org subdomain als A-Record erstellt und den MX eintrag auf diese neue Subdomain geleitet (und 1h bis zum record timeout gewartet…) und schon funktioniert’s.
MX auf einen CNAME eintrag
Ich bin mir nicht mehr genau sicher, aber ich glaube, es lag daran, dass die mail.example.com (auf die der MX-Record zeigte) ihrerseits wiederum ein CNAME auf vhosts.example.com war, dass manche Mails wehement mit der falschen Empfänger-Adresse zugestellt wurden (z.B. me@vhosts.example.com statt me@example.net), was seinerseits wieder einen Einrichtungs-Mehraufwand am Mailserver verursacht.
Ich hab’ daraus auf jeden Fall gelernt, mit CNAME-Einträgen wieder sparsamer umzugehen (auch wenn sie noch so praktisch sind…).
Page: 1 of 2
Next